Object oriented programming is the typical go-to method of programming, and it is super useful, especially in a program’s “sculpting”/exploration or design phase. The problem with it, however, is that modern computer hardware has evolved and typical OOP practices have not. The main issues are that hardware is getting more parallelized and cache-centric. What this means is that programs benefit when they can fetch data from the catch rather than RAM, and when they can be parallelized. Typical, Object Oriented Programming, it turns out, does little to take advantage of these new hardware concepts, if indeed it does not oppose them.
Data Oriented Design is a design philosophy being popularized in video game programming, where there is a lot of opportunity for both parallelization and cache consideration. I think this concept can be useful to some extent everywhere, however, and a programmer should be aware of what it is and how to make use of it. Cache speed is enormous compared to RAM, and by default, there are absolutely no considerations about it being made by programmers. This should change. Unfortunately, a lot of popular languages, developed and evolved in the concept of infinite resources, a logical fallacy, offer little to no support for cache-centric programming (Java/.Net). Fortunately, in C++, we have future. Working with DoD is going to be beneficial until (if) computer hardware ever becomes unified and the “cache” becomes gigabytes in size. Until then, however, we must work with both RAM and Cache in our designs, if they are to be performant.
To start, lets look at typical OOP and what sort of performance characteristics it has.
First off, the simple Object and an Array of them:
class Object{
public:
int x, y, z;
float a, b, c;
int* p;
};
std::vector<Object> objects;
In this example, we have various variables composed into an object. There are several things going on here:
a) The Object is stored in a contiguous segment of memory, and when we go to reference a given variable, ( x, y, z, a, b, c, p ), the computer goes out to fetch that data, and if it is not already in the Cache, it gets it from Ram, and memory near to it, and puts it into the Cache. This is how the Cache fills up, recently referenced data and data near to it. Because the cache is limited in size, it periodically will flush segments to RAM or retrieve new segments from RAM. This read/write process is takes time. The key concept here is that it also fetches *nearby* data, anticipating that you may be planning to access it sequentially or that it may be related and soon used.
b) The variable, (p), is a pointer. When this variable is dereferenced, the cache is additionally filled by that data ( and near data) additionally. Fetching memory from a pointer may cause additional catch filling/flushing in addition to merely considering the pointer itself.
c) considering the vector: objects; objects is a contiguous segment of memory and accessing non-pointer data sequentially is ideal. When element x is referenced, so then there is a good chance that x+y and x-y elements were all stored into the cache simultaneously for speedy access. Because the vector is contiguous, all of the bytes of every object are stored in sequence. The amount of objects accessible in the Cache is going to depend on the size of the Object in bytes.
We will examine an example application comparing the performance of OOP and DOD.
To begin, lets create a more realistic OOP object to make a comparison with:
class OopObject {
public:
Vector3 position, velocity;
float radius;
std::string name;
std::chrono::steady_clock::time_point creationTime;
void load() {
//initialize with some random values;
position = reals(random);
velocity = reals(random);
radius = reals(random);
name = "test" + std::to_string(radius);
creationTime = std::chrono::steady_clock::now();
}
void act() {
//this is a function we call frequently on sequences of object
position += velocity;
}
};
OK, and now the unit test, using GoogleTest:
TEST(OopExample1, LoadAndAct) {
std::vector<OopObject> objects;
objects.resize(numObjects);
time("load", [&]() {
for (auto& o : objects) {
o.load();
}
});
time("act", [&]() {
for (auto& o : objects) {
o.act();
}
});
float avg = 0;
time("avg", [&]() {
float avg1 = reals(random);
for (auto& o : objects) {
avg1 += o.radius;
}
avg1 /= objects.size();
avg += avg1;
});
std::cout << avg;
EXPECT_TRUE(true);
}
We interact with this object in a typical OOP fashion, we create a vector, dimension it, loop through, initialize the elements, then we loop through again and do the “act” transform, and then we loop through again and do an “avg” calculation.
To start programming DoD, we need to consider the Cache rather than using it by happenstance. This is going to involve organizing data differently. In Object Orientation, all data is packed into the same area and therefore is always occupying cache, even if you only care about a specific variable and no others. If we are iterating over an array of objects and only accessing the same 20% of data the whole time, we are constantly filling the cache with 80% frivolous data. This leads to a new type of array and a typical DoD Object.
The first thing we do is determine what data is related and how it is often accessed or what we want to tune towards, then we group that data together in their own structures.
The next thing we do is create vectors of each of these structures. The DoDObject is in fact a sort of vector manager. Rather than having a large vector of all data, we have series of vectors with specific data. This increases the chances of related data being next to each other, while optimizing the amount that’s actually in the cache because there’s no space taken by frivolous data.
class DoDObject {
public:
struct Body {
Vector3 position, velocity;
};
struct Shape {
float radius;
};
struct Other {
std::string name;
std::chrono::steady_clock::time_point creationTime;
};
std::vector< Body > bodies;
std::vector<Shape > shapes;
std::vector<Other> others;
DoDObject(int size) {
bodies.resize(size);
shapes.resize(size);
others.resize(size);
}
void load() {
for (auto& b : bodies) {
b.position = reals(random);
b.velocity = reals(random);
}
for (auto& s : shapes) {
s.radius = reals(random);
}
int i = 0;
for (auto& o : others) {
o.name = "test" + std::to_string(shapes[i++].radius);
o.creationTime = std::chrono::steady_clock::now();
}
}
void act() {
for (auto& b : bodies) {
b.position += b.velocity;
}
}
};
Lets look at the results, at the end will be the complete source file.
(AMD Ryzen 7 1700)
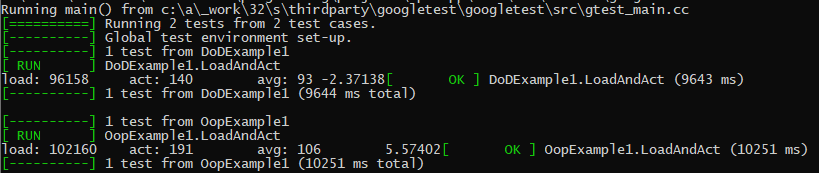
(AMD FX 4300)
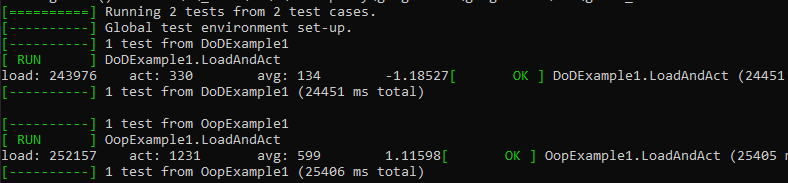
(Intel(R) Core(TM) i7-4790K)

DOD has won on every test. This is a simple example program, too. Actual programs are going to see even larger gains.
Here’s the complete source of this example: (GoogleTest C++)
#include "pch.h"
#include <vector>
#include <chrono>
#include <string>
#include <random>
std::uniform_real_distribution<float> reals(-10.0f, 10.0f);
std::random_device random;
int numObjects = 100000;
struct Vector3 {
float x, y, z;
Vector3() = default;
Vector3(float v) : x(v), y(v + 1), z(v + 2) {}
Vector3& operator+=(const Vector3& other) {
x += other.x;
y += other.y;
z += other.z;
return *this;
}
};
class OopObject {
public:
Vector3 position, velocity;
float radius;
std::string name;
std::chrono::steady_clock::time_point creationTime;
void load() {
//initialize with some random values;
position = reals(random);
velocity = reals(random);
radius = reals(random);
name = "test" + std::to_string(radius);
creationTime = std::chrono::steady_clock::now();
}
void act() {
//this is a function we call frequently on sequences of object
position += velocity;
}
};
class DoDObject {
public:
struct Body {
Vector3 position, velocity;
};
struct Shape {
float radius;
};
struct Other {
std::string name;
std::chrono::steady_clock::time_point creationTime;
};
std::vector< Body > bodies;
std::vector<Shape > shapes;
std::vector<Other> others;
DoDObject(int size) {
bodies.resize(size);
shapes.resize(size);
others.resize(size);
}
void load() {
for (auto& b : bodies) {
b.position = reals(random);
b.velocity = reals(random);
}
for (auto& s : shapes) {
s.radius = reals(random);
}
int i = 0;
for (auto& o : others) {
o.name = "test" + std::to_string(shapes[i++].radius);
o.creationTime = std::chrono::steady_clock::now();
}
}
void act() {
for (auto& b : bodies) {
b.position += b.velocity;
}
}
};
template<typename Action>
void time(const std::string& caption, Action action) {
std::chrono::microseconds acc(0);
//each action will be executed 100 times
for (int i = 0; i < 100; ++i) {
auto start = std::chrono::steady_clock::now();
action();
auto end = std::chrono::steady_clock::now();
acc += std::chrono::duration_cast<std::chrono::microseconds>(end - start);
}
std::cout << caption << ": " << (acc.count() / 100) << "\t";
};
TEST(DoDExample1, LoadAndAct) {
DoDObject dod(numObjects);
time("load", [&]() {
dod.load();
});
time("act", [&]() {
dod.act();
});
float avg = 0;
time("avg", [&]() {
float avg1 = reals(random);
for (auto& o : dod.shapes) {
avg1 += o.radius;
}
avg1 /= dod.shapes.size();
avg += avg1;
});
std::cout << avg;
EXPECT_TRUE(true);
}
TEST(OopExample1, LoadAndAct) {
std::vector<OopObject> objects;
objects.resize(numObjects);
time("load", [&]() {
for (auto& o : objects) {
o.load();
}
});
time("act", [&]() {
for (auto& o : objects) {
o.act();
}
});
float avg = 0;
time("avg", [&]() {
float avg1 = reals(random);
for (auto& o : objects) {
avg1 += o.radius;
}
avg1 /= objects.size();
avg += avg1;
});
std::cout << avg;
EXPECT_TRUE(true);
}
