Like I said earlier, this post is a sort of introduction to programming, however, it is not a typical, “Hello World” introduction. We’ll be using C++ and inline Assembly to investigate what exactly is going on in a program and C++. The following will be explained:
- what a C++ program is and looks like to a computer
- what variables are and how the stack and memory works
- what functions are and how they work
- how pointers work
- how math and logic works, such as when you evaluate an equation
What a C++ program is and what it looks like to the computer
C++ and any programming language is just a bunch of words and syntax used to describe a process for the computer to perform.

You write a bunch of stuff, and the computer does exactly what you commanded it to. That said, while a program is a series of words and syntax to us, to the computer, it ends up being quite different. Computers only understand numbers, so somewhere between when a program is written and when it is executed by the computer, it gets interpreted from the programming language into numbers – Machine Code.
For example, the following program:
r = x + x * y / z - z * xLooks like this in Machine Code:

Programming languages exist for a several reasons:
- to provide an alternative to writing in Machine Code
- to make writing maintainable and manageable code bases possible
- to allow programmers to express themselves in different ways
- to accomplish a task with efficiency given a language customized to that task
Finally, the basic C++ program that writes, “Hello World!”, to the console screen:
int main(){
std::cout << "Hello World!";
return 0;
}In Machine Code, it looks like this:
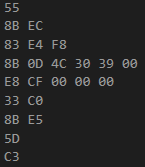
C++ is quite the improvement.
The language that translates closely to Machine Code is Assembly Language. While both Machine Code and Assembly Language are unpractical to work with, Assembly Language is actually something people do use, and we are going to use it to link what’s going on in the computer to what’s going on in C++.
Before we can move into Assembly, however, we need to review some basics of how programs work.
Memory
As we know, computers work with numbers, and a program is ultimately a bunch of numbers. The numbers are stored in the the computer in a place called memory, and lots of them, more numbers than you could count in your lifetime. It can be thought of as an array, grid or matrix where each cell contains a number and is a specific location in memory.

A visualization of memory.
These cells exist in sequence and that sequence describes its location. For instance, we could start counting memory at cell 1, and go to cell 7, and each of those locations could be referred to by their sequence number: 1 to 7.
The numbers in memory can represent one of two things:
- a Machine Code or operand used to execute a command
- some sort of Variable – an arbitrary value to be used by, or that has been saved by, a program
In programming languages such as C++, variables are referred to using names rather than their sequence number, and Machine Code is abstracted away with verbose language.
A snippet of C++ that declares three variables and prints them out.

The same snippet in Assembly; for glancing only.

The Stack: a type of Memory for Variables
Whenever a Variable is declared, it gets allocated in an area of Memory called the Stack. The Stack is a special type of Memory which is essential to how a C++ program executes. When a Variable enters scope, it gets allocated onto the Stack, and then later, when it exits scope, it’s removed from the Stack. The Stack grows in size as Variables enter scope and shrinks as Variables exit scope.
In C++, curly braces “{ “ and “ } “ are used to define a variable’s scope, also known as a block or epoch.
A C++ program with several blocks:
void main(){ //begin block a:
//x is allocated, stack size goes to 1
int x = 0;
{ // begin block b:
// k, l and m are allocated, stack size goes to 4
int k = 2, l = 3, m = 4;
// an example operation
x = k + l + m;
} // end of block b, stack size shrinks back to 1
// - back to block a - y is allocated, stack size goes to 2
int y = 0;
{ // begin block c:
// l and o are allocated, stack size goes to 4
int l = 12, o = 2;
// an example operation
y = l * o;
} // end of block c, stack size shrinks back 2
// - back to block a - z is allocated, stack size goes to 3
int z = 0;
// an example operation
z = x - y;
// write result, z, to the console
std::cout << z << std::endl;
} // end of block a, stack shrinks to size 0

x86 Assembly Brief on the Stack
Assembly is really simple. Simple but lengthy and hard to work with because of its lengthiness. Lets jump right in.
A line of Assembly consists of a command and its operands. Operands are numbers of course, but these numbers can refer to a few different things: Constants ( plain numbers ), Memory locations (such as a reference to a Stack Variable), and Registers, which are a special type of Memory on the processor.
The Stack’s current location is in the esp register. The esp register starts at a high memory location, the top of the stack, such as 1000, and as it grows, the register is decremented, towards say, 900 and 500, and eventually to point where the stack can grow no further. General purpose registers include eax and are used to store whatever or are sometimes defaulted to with certain operations.
There are two commands that manipulate the stack implicitly:
- push [operand]
put the operand value onto the Stack, and decrement esp
- pop [operand]
remove a value from the Stack, store it in the operand register, and increment esp
Registers:
- esp
the Stack’s top, moves up or down depending on pushes/pops, or plain adds/subtracts.
- eax
a general purpose register
Given these two instructions we can create and destroy stack variables. For instance, similar to the program above but without the example equations:
_asm{
push 0 //create x, with a value of 0
push 2 //create k
push 3 //create l
push 4 //create m
//do an equation
pop eax //destroy m
pop eax //destroy l
pop eax //destroy k
push 0 //create y
push 12 //create l
push 2 //create o
//do an equation
pop eax //destroy o
pop eax //destroy l
push 0 //create z
//do an equation
pop eax //destroy z
pop eax //destroy y
pop eax //destroy x
}Another way to manipulate the Stack/esp involves adding or subtracting from esp. There is an offset in bytes which is a multiple of the Stack alignment, on x86, this is 4 bytes.
add esp, 12 // reduce the stack by 12 bytes – same as 3 * pop
sub esp, 4 // increase the stack by 4 bytes – same as 1 * pushThe difference in usage is that add and sub do not copy any values around. With add, we trash the contents, and with sub, we get uninitialized space.
Once Stack space has been allocated, it can be accessed through dereferencing esp. Dereferencing is done with brackets.
[esp] // the top of the stack, the last push
[esp + 4] // top + 4 bytes, the second to last push
[esp + 8] // top + 8 bytes, the third to last push
//[esp – x ] makes no senseAdding in the example equations requires some additional commands:
- add [add to, store result], [ operand to add ]
adds the operand to register
- sub [subract from, store result], [ operand to subtract ]
subtracts the operand from the register
- mul [operand to multiply by eax, store in eax ]
multiplies the operand by the eax register
- mov [ copy to ], [ copy from ]
copies a value from a Register to Memory or vice versa.
_asm{
push 0 //create x, with a value of 0
push 2 //create k
push 3 //create l
push 4 //create m
//k + l + m;
mov eax, [esp + 8] // copy k into eax
add eax, [esp + 4] // add l to eax
add eax, [esp] // add m to eax
add esp, 12 //destroy k through m
//store the value in x
mov [esp], eax
push 0 //create y
push 12 //create l
push 2 //create o
// l * o
mov eax, [esp + 4] //copy l into eax
mul [esp] //multiply o by eax
add esp, 8 //destroy l and o
//store the value in y
mov [esp], eax
push 0 //create z
//x - y;
mov eax, [esp + 8]
sub eax, [esp + 4]
mov [esp], eax //write to z; z = -15
add esp, 12 //destroy z through x
}
Functions
Functions are a way to associate several things:
- A Stack block
- Code
- A useful name
As we know, rather than writing out the same code over and over, to reuse it, we can use a function.
But that is not the end of what functions are, they are also Named Code Segments, a segment of code with has a useful name, a name that both describes what the function does, and that be used to call that function in the language.
In C++ functions have four properties:
- return type
- function name
- parameters
- function body
And the following prototype:
[return type] [name]([parameters]){[body]}
In C++ a sum function would look like so:
int sum( int x, int y ){
return x + y;
}In assembly to sum these two values we’d do the following:
push 5 // y = 5
push 4 // x = 4
mov eax, [esp] //eax = x
add eax, [esp+4] //eax = 9
add esp, 8 //clear stackYou can see there are three stages here:
- Setting up the function’s parameters using push
- the actual function code
- resetting the stack
We are also missing three things, the function name, the return type, and actually calling the function. In assembly, a function name is the same as a C++ label:
sum:
Now comes an interesting part – assembly – since we can do anything in it, is going to implement something called a: Calling Convention – how the function’s parameters are passed, how the stack is cleaned and where, and how the return value is handled.
In C++ the default calling convention is called cdecl. In this calling convention, arguments are pushing onto the stack by the caller, and in right to left order. Integer return values are saved in eax, and the caller cleans up the stack.
First off, to actually call a function we could use a command, jmp. Jmp is similar to the C++ goto statement. It sends the next instruction to be processed to a label. Here’s how we could implement a function using jmp:
_asm{
jmp main
sum: //sum function body
mov eax, [esp+4] //we have a default offset due to the return address
add eax, [esp+8]
jmp [esp] //return to: sumreturn
main: //main program body
push 5 //we plan to call sum, so push arguments
push 4
push sumreturn //push the return address
jmp sum //call the function
sumreturn:
add esp, 12 //clean the stack
//result is still in eax
}To make this much easier, there are additional instructions:
- call [operand]
automatically pushes the return address onto the stack and then jumps to the function
- ret [ optional operand ]
automatically pops the return address and jumps to it
These instructions wrap up some of the requirements of function calling – the push/pop of the return address, the jmp instructions, and the return label. With these additional instructions we’d have the following:
_asm{
jmp main
sum:
mov eax, [esp+4] //we have a default offset due the to return address
add eax, [esp+8]
ret
main:
push 5 //we plan to call sum, so push arguments
push 4
call sum
add esp, 8 //clean the stack
//result is still in eax
}
In other calling conventions, specifically x64 ones, most parameters are passed in registers instead of on the stack by default.
See: https://en.wikipedia.org/wiki/X86_calling_conventions
With cdecl, every time we call sum, we have an equivalent assembly expansion:
push 5 //pass an argument
push 4 //pass an argument
call sum //enter function
add esp, 8 //clear argumentsRecursive functions run out of stack space if they go too deep because each call involves allocations on the stack and it has a finite size.
Pointers
Pointers confuse a lot of folks. What I think may be the source of the confusion is that a pointer is a single variable with two different parts to it, and indeed, a pointer is in fact its own data type. All pointers are of the same data type, pointer. They all have the same size in bytes, and all are treated the same by the computer.
The two parts of a pointer:
- The pointer variable itself.
- The variable pointed to by the pointer.
In C++, non-function pointers have the following prototype:
[data type]* [pointer variable name];
So we actually have a description of two different parts here.
- The Data Type
this is the type of the variable that is pointed to by the pointer.
- The Pointer Variable
this is a variable which points to another variable.
What a lot of folk may not realize, is that all Dynamic Memory ultimately routes back to some pointer on the Stack, and to some pointer period – if it doesn’t, that Dynamic Memory has been leaked and is lost forever.
Consider the following C++
int* pi = new int(5); With this statement, we put data into two different parts of memory; the first part is the Stack, it now has pi on it, the second, int(5), is on the heap. The value contained by the pi variable is the address of int(5). To work with a value that is pointed-to by a pointer, we need to tell the computer to go and fetch the value at the pointed-to address, and then we can manipulate it. This is called Dereferencing.
int i = 10; //declare i on the stack
int* pi = &i; //declare pi on the stack and set it's value to the
//address of i
*pi = *pi + 7; //dereference pi, add 7, assign to i
// i = 17So in assembly, there is an instruction used to Dereference:
- lea [operand a ] [operand b]
Load Effective Address, copy b into a
lea a, value performs the following process:
- stores value in a
- such that
lea eax, [ eax + 1] will increment eax by 1
- and
lea eax, [ esp + 4 ] takes the value of esp, an address, adds 4, and stores it in eax
_asm {
//initialization
push 10 //a value, i
push 0 //a pointer, pi
lea eax, [esp + 4] //store the address of i in eax
mov [esp], eax //copy the address of i into pi
//operations
mov ebx, [esp] //dereference esp, a value on the stack, and get the value
//of pi - the address of i
add [ebx], 7 //dereference pi and add 7, i == 17
//[esp+4] now == 17
add esp, 8 //clean the stack
}So these examples pointed to memory on the stack, but the same process goes for memory on the heap as well, that memory is just allocated with a function rather than push.
Logic and Math
Probably the key aspect of programming is the use of if-statements. An if-statement can be a long line of code and obviously that means it turns into lots of assembly statements. What you may not realize though, is that a single C++ if-statement actually often turns into multiple assembly if-statements. So lets examine what an if-statement is in assembly.
Consider the following C++:
int x = 15;
if( x == 10 ) ++x; Can result in the following assembly:
_asm {
push 15 // x
cmp [esp], 10 //compare x with 10 and store a comparison flag.
jne untrue //jump to a label based on the comparison flag.
//in this case, ne, jump if not-equal.
//since 15 != 10, jump to untrue and skip the
//addition. If x was 10, it would be executed.
add [esp], 1 //increment x by 1
untrue:
//proceed whether it was evaluated true or not
add esp, 4 //clean stack
}If–statements generate multiple jumps when there are logical operators in the statement. This results in an if-statement property called short-circuiting. Short Circuiting is a process in which only some of the if-statement may be executed. In the case where the first failure of a logical operation evaluates the if-statement as false, the subsequent logical operations are not evaluated at all.
An example of and logical operator:
int x = 10, y = 15;
if( x == 10 && y == 12) ++x; _asm {
push 10 // x
push 15 // y
//the first statement
cmp [esp+4], 10 //if the current logic operation evaluates
jne untrue //the statement to false, then all other
//operations are skipped.
//in our case it was true so we continue to
//the second statement
cmp [esp], 12 //this comparison is false, so we jump
jne untrue
//only evaluated if both and operands were true
add [esp+4], 1 //increment x by 1
untrue:
//proceed whether it was evaluated true or not
add esp, 8 //clear stack
}
In the above example, if x had been != 10, then y == 12 would not have been evaluated.
An example with the or logical operator.
int x = 10, y = 15;
if( x == 10 || y == 12) ++x; _asm {
push 10 // x
push 15 // y
cmp [esp+4], 10
je true //if the first statement is true, no need to
//evaluate the second
cmp [esp], 12 //if the first statement evaluated false,
jne untrue //check the next statement
true:
//evaluated if either or operand was true
add [esp+4], 1 //increment x by 1
untrue:
//proceed whether it was evaluated true or not
add esp, 8 //clear stack
}
Logical order of operations is going to be left to right order, which ensures that sort circuiting works as expected.
Back to the top, we had the following equation:
r = x + x * y / z - z * xThis entire equation needs to be evaluated, and as you realize, this is a bunch of assembly steps. The order in which the steps execute is almost certainly not left to right, but is some sort of logical order-of-operations which is also optimized to be speedy and effecient.
The equation has four steps:
a = + x*y/z
b = + x
c = + z*x
result = a + b - cAgain, the order is going to respect mathematical order of operations, and try to run efficiently on the computer. Here’s how it may turn out:
_asm {
//setup
//all of these variables are integers and the operations are integer
push 10 //x
push 15 //y
push 2 //z
//cache x its used 3 times: ebx = x
mov ebx, [esp+8]
//eax = x*y/ z
mov eax, ebx
mul [esp+4]
div [esp]
//ecx = eax + x
add eax, ebx
mov ecx, eax
//eax = ez*ex
mov eax, [esp]
mul ebx
//finally, subtract: perform ( ex*ey/ez + ex ) - (ez*ex) = ecx
sub ecx, eax
//result is in ecx
add esp, 12 //clear stack
}On a final note, if you want to get output from these examples into c++, here’s an easy way for Visual Studio:
int main(int argc, char**argv){
int result =0;
_asm{
mov eax, 5
mov dword ptr[result], eax
}
std::cout << result;
std::cin.get();
return 0;
}
That’s it for this post! In the future I’ll mostly post about C++ programming itself. I would love to hear your comments below! Good Luck!

{kind=link}
Thank you for this article. It’s very important and useful information!
LikeLiked by 1 person